Blog
Unit Tests as Experiments
11 May 2017
One of the strategies I’ve been using lately is creating unit tests when I have a problem that I don’t understand fully. It’s an easy way to encode a set of assumptions (test fixture setup), try out potential ways of solving a problem, then check whether it worked (assert some expected outcome).
Since I often work without a REPL (Java 9 will change this), I need easy ways to run programs that are small and malleable. I also work with complex runtimes (magical, auto-configured Spring systems are one of many examples) and it helps to be able to simulate a complex system by setting up test fixtures that manage that complexity while providing direct access to the thing I need to test.
I find this approach is also helpful when trying to work with an unfamiliar API. Sometimes my mental model of an API’s behavior doesn’t quite match reality, and a test is usually a quick way to verify an hypothesis about what outcomes I should expect.
The BDD way of structuring tests fits this approach pretty well. Given some initial conditions, when this thing occurs, then I expect this outcome. The difference is that instead of encoding requirements, I’m encoding hypotheses.
Role-based thinking – an experiment
12 November 2014
I have previously written about the importance of thinking in terms of functional behavior rather than merely in terms of capability. That is, why we are doing something is at least as important as how we are doing it. Now, maybe I’ve been overdoing the whole Scrum thing lately (not likely), but I’ve started thinking more in terms of roles when I formulate tasks for my team. My old way of thinking (which I still frequently fall back into) goes something like this:
We have a lot of technical debt. We need to remove unused dependencies from our build. We need to improve our test coverage. We need to improve our release process. We need to be able to onboard new team members more easily. We need a more robust continuous integration environment. We need to make troubleshooting easier for production support. We need to fully externalize our application configuration. We need to minimize the impact of poor change management on the part of our upstream dependencies….
There’s nothing wrong with working through a task list such as this, but it does have shortcomings. First, it (often) leads us to prioritize personal preference over team productivity. When each team member pursues these types of activities in isolation, the outcome is not always generalizable and so the impact is dampened.
Second, it is difficult to justify these activities from a business perspective. The way I formulated the descriptions, there are no real quantifiable outcomes. While the objectives all sound good, we have to ask, what is the opportunity cost here? What are the tangible benefits to the team members who aren’t engineers? What are the benefits to the stakeholder the team is trying to serve?
Finally, these sorts of to-do lists are often very difficult to estimate against. How do we know when is a task done? Which parts of the task have highest priority? The answer, typically, is when the person who completes the task is happy with the result. That’s not very well-structured, and in fact it smells like an anti-pattern. (Like when engineers write acceptance tests. But I digress.)
So, my experiment, (which is ongoing, so I don’t have outcomes to report), is to take the concept of a user story and extend it to the various functional roles within our team. So there will be “role stories” but they can be formulated as typical user stories, and I will refer to them as user stories throughout. This concept is actually not unusual, or shouldn’t be, but I’ve only seen hints of this thinking on teams that I’ve worked with. I’m describing it here for my own benefit and because I assume many other teams out there fail to take a structured approach to self-organizing. (Certainly true of most of the teams I have worked on.)
So the first user stories from my example would belong to the build manager. As a build manager I need to remove unused dependencies from our modules… etc. By formulating the tasks in this way, we can not only improve the quality of the product (which will benefit the stakeholder), we allow team members to have input into the tasks that they are assigned. It is a mechanism to address stressors and productivity inhibitors. This improves morale, and, done correctly, improves competence.
The next story would be for the quality assurance role. It would go something like this: as the quality assurance owner, I want to improve our test coverage so that defects raised by testers are reduced by at least 50%. Acceptance criteria will be branch coverage of 80% in the following problem modules: … Of course, if the testers continue to raise defects, the issue would need to be revisited. Presumably the team would agree that this story makes sense, and would be able to break it down into small tasks, which should always be done.
The next problem, facilitating team growth, is one that has been a struggle for most teams I’ve worked on. For that reason, I tend to think that it’s a difficult problem to solve. It can often be decomposed into small tasks and the burden shared among multiple members of the team, which I see as an upside. As a team member, I want to assist new team members by reducing the time it takes them to begin being productive without impacting the delivery of the sprint backlog. I’ll know this is possible when we have an accurate deployment diagram, a project overview guide, and a workstation setup guide.
Where this thought experiment starts to get interesting is when we think about maintaining the “product” of these user stories. (Something the product owner really should care about.) So when a backlog shows a story like, as a product user I need to be able to search for widgets, we see that there are implied user stories (role stories!) that exist in parallel. That is, as an engineer I need to create a Maven project that exposes an HTTP-based search API, and also, as a build manager I need to add new projects into our continuous integration environment, and of course as a test designer, I need to write functional tests against all HTTP-based services using SoapUI. (You do test your code, right?) So the interesting property of this thought experiment is the natural decomposability of user stories into tasks, and those tasks are themselves a sort of user story (role story, in my terminology). Add stories for a technical writer, deployment manager, and production support team and you’ve avoided a lot of technical debt.
The other point that must be mentioned, thought it is obvious, is that the tasks associated with these stories may be completed by the same person. One person may perform multiple functional roles. For example, a tech lead may often function as an engineer, team growth facilitator, build manager, documentation maintainer, etc., possibly all within the same day.
Functional decomposition, which is really all I’m talking about, helps to narrow the scope of a task in order to make it manageable. Whether we’re writing use cases, user stories, software, or documentation, functional decomposition is an important tool that is often ignored yet very valuable.
On Not Being Ignorant
06 November 2014
One of the more surreal events that has happened to me in my many programming jobs was the time I was contacted about a support issue for a web service that I knew almost nothing about. I don’t remember what that issue was, but I do remember how the situation came about.
I had been working on a web application that displayed search results from a service that was not provided by the application. The search went through another service that had a fairly large database of information, some of which was directly useful to our end users. During development and testing, no performance problems were noted and even in production things seem to be fine when we tested it. As it turns out performance was terrible under load, exactly when our users would need the service.
We opened a support ticket with the team that owned the service, but were not getting quick responses. So I did some research. I found their source code, got a connection into their test database, and was able to determine the kinds of queries that were needed to support the part of the service that we were using. Within about 15 minutes I was able to determine the cause and propose a solution, and I did so on the support ticket that my team had opened.
Somehow, the fact that my name was attached to a viable solution on that ticket led someone to believe that I knew something (about that service anyway). In a sense, I did. In the short time I spent examining the internals of that service, I learned several things. First, that I was not the first person to try to track down a performance problem in that system. Second, I would certainly not be the last person to do so. Third, I realized that the service could never do what it was intended to do without being rewritten. Fourth, I realized that the application ownership and support model in use by this particular corporation was pretty dysfunctional. (Well, I knew that before…)
The reason I started writing about this debacle is that it gave me a way to frame a few thoughts on “not being ignorant.” Because everyone is ignorant about most things (really), it’s worth pointing out that not being ignorant is a very selective thing.
So what really bothered me about this dysfunctional situation was really an acquiescence to ignorance. Let me cover some examples that are specific to this situation, but keep in mind that they reflect an underlying pattern.
I don’t know why this SQL statement is slow, but I bet if I keep adding indexes eventually I’ll find one that works (and hopefully remember to delete the indexes that don’t have any value).
I want to search this column in a case-insensitive way, so I’ll convert the search value and the column value to the same case in my SELECT statement and assume it will perform well.
I know I need to limit the number of results I return to my users, but all I can think to do is have my ORM give me a list and then send back a slice; that should be good enough.
Want to guess what the pattern is? It’s a pain-minimization strategy. It’s like saying, “being ignorant is painful, so I’ll gain just enough knowledge to make the pain go away (temporarily).” Unfortunately, this strategy tends to produce a lot of repetitive variations of the same situation. Hence, I consider it to be a suboptimal lifestyle choice.
What were the effects of this strategy on the application I’ve been talking about? Obviously performance issues are one: exponential response times under moderate load can never be good. Maintenance costs were another: every performance issue had to be addressed as it was discovered. SLA adherence couldn’t be taken seriously, which in some situations can be a pretty high-stakes risk to take. As the application evolved, the possibility of proactive risk management became impossible, which is a big clue that a re-write is in order.
The opposite of ignorance is knowledge. Finding a better strategy for problem-solving is a valuable piece of knowledge. Don’t underestimate it.
Push-based Server Automation
29 April 2014
A couple of years ago, I wrote some server automation scripts which I used to remotely manage servers from my laptop. I thought I was being clever and original, since I was only aware of Puppet and Chef at the time, and both require the installation of an agent on the remote server. But I recently discovered that Ansible and Salt Stack both support push-based automation, so it seems I am not so original after all.
My scripts supported a number of useful features, so I thought it would be worth writing them down before I forget. It could push files over SSH, by default to /tmp. Once uploaded, a file would be checksummed with MD5 and the script would error out if it didn’t match. I frequently uploaded compressed archives and then expanded them on the server, which was pretty efficient. I had the ability to run the scripts from Windows machines using the tools provided by PuTTY, using batch scripting, PowerShell scripting, or a port of the Bash shell. I had the ability to enter a username and password once and re-use them for multiple commands. (I sent files over SCP with individual calls, so password-reentry was painful when targeting a 9-node cluster.) Password entry was not logged to the console, for security reasons. When different usernames were needed, a password prompt was still provided only once. (In retrospect, the ability to use keys with ssh-agent would have been fantastic, but I had no control over that.) The scripts could also run remote commands to do things like restart application servers and verify or update file permissions. (Some admins were not careful about not using the root user to restart the app servers, which caused a lot of files to become owned by root, and subsequent restarts that were done correctly would fail in strange ways, so permission verification was a big time-saver.)
The other nice thing about my scripts is that I kept them all versioned in our SCM. Any time I needed to push releases to production, my main task was to enter the correct version number(s) of the components I was pushing, and I could then tag that change permanently in the SCM. Deployments got a lot more boring when this stage was reached, which was really nice. I’m not a sysadmin and don’t really care to be one. Automating the hassles of admin work helps me to stay sane.
If you actually have decision-making authority, I suggest you do better: invest in real automation tools. Your good developers will be happier. Your not-as-good developers won’t screw things up by accident so easily. (This was all-too-frequent from people I won’t name, and cost me a lot of sleep.)
Test-driven Troubleshooting
03 April 2013
Lately I’ve found myself writing what I would consider to be odd unit tests. Odd because they are not written to test my code, or really to test any code that is used in my current project. Rather, these tests have served as proofs of the behavioral characteristics of target deployment environments.
One test I wrote was to demonstrate that a particular filesystem location was not writable from within an app server. This had been preceded by proof that assuming the user credentials used by the app server process did indeed have write access. In this situation, quite strangely, the app server had failed to acquire write permissions. Since the application failures we were seeing appeared to be due to this filesystem permissions issue, no further troubleshooting effort was required on my part because I had proven that the failure was not in the application layer.
Another test I wrote to demonstrate that certain HTTP headers were not being passed to a Java Servlet container. Additionally, the test showed that the container was not responding appropriately when those headers were subsequently enabled. Why did this test matter? By demonstrating that the application was not defective, I was able to avoid modifying application code to work around an improperly configured environment.
Finally, I wrote a test to prove that certain response characteristics of an OAuth-protected resource were incorrect. This would have been extremely difficult to accomplish solely by use of runtime testing (e.g. navigation in a browser) because the OAuth calls were not under the control of the browser. By using automated tests, I not only shortened my debugging time, I also was able to send my test case to another engineer for verification.
By writing tests at the start of problem investigations, I am able to see the impact of changes. (It is often the case that an attempt to fix a problem will create a new problem elsewhere.) I am able to repeat my test many times with minimal effort. I am also able to share my tests with others; one benefit of that is that I may make mistakes that are more easily spotted by others.
Because of all this, I have lately been thinking of unit tests more along the lines of mathematical proofs, rather than just a way to exercise a set of CPU instructions. Properly constructed, a unit test can serve as a very practical sort of mathematical proof. And in my case, these proofs helped to spare me from needless time-wasting activities. By rigorously asserting the conditions required for success or failure, I was able to repeatedly and consistently isolate the causes of these various problems I had encountered. In all of these cases, I would have saved even more time had I started my troubleshooting efforts by writing the test first. Test-driven troubleshooting isn’t always possible, but I do recommend that you consider it, especially if you value your time and do not wish to waste it on needless activities.
Improving cmd.exe
12 August 2012
While out-of-the-box features for Windows’ command interpreter (cmd.exe) have mildly improved over the years (command completion turned on by default comes to mind), the defaults are still boring. Really, really boring. And kinda ugly, too.
Beyond the boring and the ugly, however, stands the dysfunctional. A tiny scroll buffer means you will quickly and easily lose data. Mouse support is turned off by default. The window is too small by default. The font could be better…
So, to spare you, the reader, the time needed to fix all those settings, I created some shortcuts (.lnk files) that will present you with reasonable defaults. You can download them all in a zipfile, or individually select the ones you’re interested in.
Here’s a screenshot with four examples:
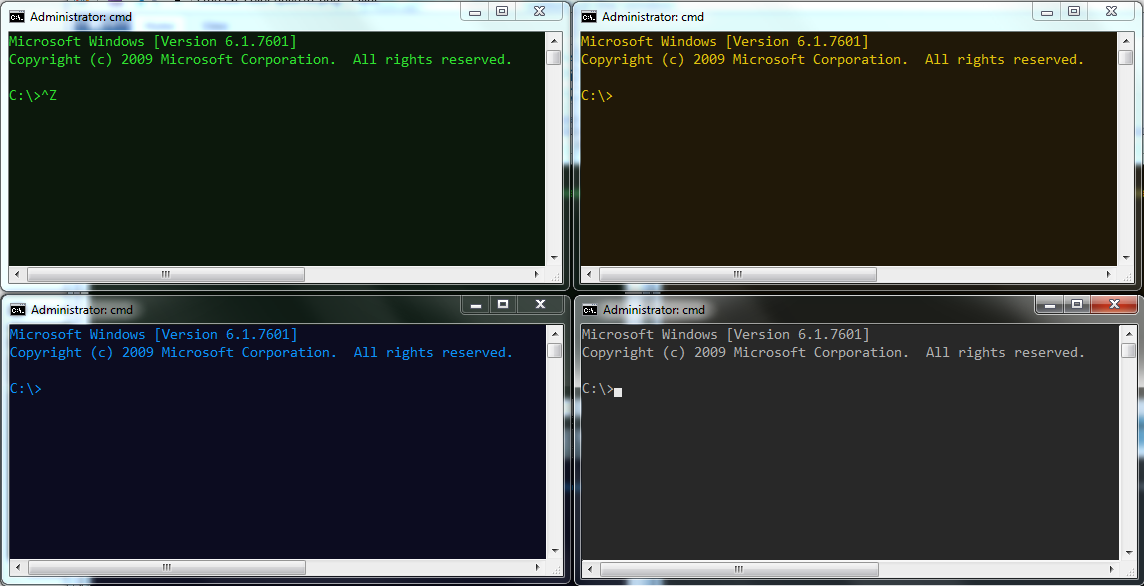
And here are the individual links:
Oracle XQuery Bug?
15 February 2012
I’ve spent the last 2 weeks on a super-secret project to slice and dice (and search, aggregate, and transform) XML in a Oracle database using the Hibernate ORM tool. Okay, maybe it’s not super-secret, but it is super-fun, and the kind of project that might stir up the world’s tiniest dust cloud of enviousness in perhaps one or two of my peers. Seamlessly querying XML and relational data is definitely useful at times. But I digress…
I started writing this post because I seem to have found a bug in Oracle’s XQuery support. As I so often do, I tried something just to see what would happen. I was not disappointed, because what happened was interesting. I ran a query like this:
select
XMLQuery('fn:distinct-values(/document/parent/child[@name])'
passing x.OBJECT_VALUE returning content).getClobVal()
from
xmltype_table x
where
XmlExists('/document/author/name[text() = $name]'
passing x.OBJECT_VALUE, 'Frederick' as "name")
;
This query was supposed to return the distinct values found in the attribute name on all elements named child that descend from parent which descends from document. As you can see, I did not get the result I expected:
ORA-00600: internal error code, arguments: [qctcte1], [0], [], [], [], [], [], [], [], [], [], []
00600. 00000 - "internal error code, arguments: [%s], [%s], [%s], [%s], [%s], [%s], [%s], [%s]"
*Cause: This is the generic internal error number for Oracle program
exceptions. This indicates that a process has encountered an
exceptional condition.
*Action: Report as a bug - the first argument is the internal error number
I honestly expected that the query would return a result. I ought to be able to get a set of distinct attribute values, just like I can get a set of distinct element values. At the same time, I also thought that in the worst case I would get a syntax error, or perhaps some other indication that I was attempting to use the query system in an unsupported manner.
I’ve been working with Oracle databases for 11 years now, and I believe this is the first time I’ve found a real bug. Considering the complexity of the full XQuery specification combined with a relational database engine, bugs are pretty much inevitable. That said, this is a great example of a case for automated regression testing. It’s probably also an example of a use case that may have been thought of but never got enough priority to be implemented.
One thing I do know: an ORA-00600 is a great thing to discover before you promise to deliver some piece of functionality. For now, my code will have to sort through attribute values on the client side.
Unhelpful JSF Error
07 December 2010
I certainly haven’t the time to blog about every unhelpful error message I find, especially not when it comes to frameworks. Good error handling is an art, and even the best projects aren’t likely to get it all right. And then there’s JSF. Or, at least, JSF as I’m using it now: the 1.2 API, MyFaces, ICEfaces, all running on Jetspeed 2. I’ve become numb to the bad error messages, mostly. You get used to them after a while, and even start to understand them.
This particular case had me up until midnight with nothing but frustration to show for it. After a bit of sleep (one of the key elements of software debugging that is often overlooked) it dawned on me what my problem was. Consider the code:
public class MyBean
{
enum MyEnum {
VAR1,
VAR2;
public String getTitle() {
return name().toLowerCase();
}
}
…
}
And the related facelet markup:
#{myEnumValue.class} is titled '#{myEnumValue.title}'
It seemed to be straightforward, but I kept getting this error message:
Property 'title' not readable on type java.lang.String
And what kept bugging me was the fact that #{myEnumValue.class} worked when it was by itself (it would output MyBean.MyEnum). I could clearly see the class name, and it looked just fine. But as soon as I added in the title property, I would get the error message again. Obviously myEnumValue was not a String, so why does the error message say that it is?
As it turns out, my Enum wasn’t public, and so apparently the methods on it could not be invoked. Rather than telling me that, the expression evaluator decided to coerce the Enum into a String and then see if the property I wanted was part of the String class. It wasn’t. Here’s the solution:
public class MyBean
{
public enum MyEnum {
…
}
}
So there you have it: one more strange error message deciphered. I hope others will spend less time tracking down these types of errors than I do.
And the real moral of the story? Well, first, error handling is hard. While string coercion may be a good strategy for this situation, the fallback error message proves unhelpful. Better to capture the message that triggered the fallback and return it instead. Unfortunately, that requires that your error handling strategy can maintain such a message and know when to use it. So a second moral is, be prepared for error handling to get much more complex as your requirements expand.
DNS aliasing: panacea?
18 June 2010
One tool that seems to be underused, at least in most corporations I’ve worked at, is the trusty DNS alias (called a CNAME record). Pretty much everybody understood the value of using DNS names as opposed to IP addresses (with some minor, unmentionably dull exceptions) but it wasn’t until I was at Sprint that I saw use of aliases. Even at that, they were just beginning to make use of them, having built a great many interdependent systems without the use of aliases, which is, as we shall see, problematic for just about everyone. So, from here, I will assume that you, the reader, are not so poorly configured as to have servers directly addressing each other by IP address. If you do, fix that problem first; come back to this when you’re done.
What happens when you build a number of multi-tier applications? You start to see a proliferation of interconnected servers, with applications, databases, services, etc. all communicating with each other. What’s the problem? Change. Change becomes very difficult. The reason is that as the number of systems grow, it becomes increasingly difficult to know exactly which servers each application depends on. In fact, addressing systems by a single host name is really no different than using IP addresses in a multi-tier scenario.
Let’s try a hypothetical scenario. If I have a dozen database servers, say db01 - db12, what happens when I want to build a new server and use it as a replacement for the existing db-08? Well, in order to migrate existing applications, we will have to rename the existing db08 and name the new server db08. This is a bad idea. The alternative, typical way is not much better: alter the configuration of every system that depends upon db08 to point to the new db13. Particularly if configuration changes require restarts for your applications, you can see that downtime is more or less inevitable.
Now, if you had chosen to do what I propose, which is to use DNS aliases, not only do you not suffer the problems I described, you also gain certain advantages. But I guess at this point I should digress with an example of a DNS aliasing scheme, so that the situation is clear. With aliasing, the goal is to name systems according to their business or application function. So if we have, say, a payroll application, we can use “payroll” as an alias for the server hosting payroll. Now certainly a database will be needed, so we might call it something like payroll-oltp, and perhaps have a separate payroll-olap for reporting purposes. We can also assume that this is a legacy system with a newly-built web front-end, which we can call payroll-web. Now, it is quite possible that all four of these aliases could point to one and the same server: this does not matter for my hypothetical scenario. The point is, each application should have its own unique set of aliases.
Now that we have our aliases set up, what happens if we decide our database is too slow? Well, assuming we can do real-time replication, we set that up and then simply alter the DNS alias to point to the new server, and (assuming no application restarts are necessary) things will continue to function as normal. Obviously I’m oversimplifying, but the point is that you have separated your application’s resource concerns from your physical hardware implementation. Your application’s configuration has been decoupled from your DNS configuration.
I should also point out that clients (users) can also benefit from aliasing. If you have hundreds of users connecting to http://swds19/ to access an application and you decide to migrate it to http://swdx30/, not only do you have to tell the users, they have to update any bookmarks they have. Any documentation containing this information, such as training materials, would also need to be changed. By using a well-thought-out alias, you protect yourself against change and avoid confusing and frustrating your users. Should you continue to use your standard naming convention to address each server? Absolutely. However, those types of names are for administrators, not for applications, and most certainly not for users. Under my proposed schema, every host should have a minimum of 2 names: a conventional name for sysadmins, and a meaningful alias for an application or its end users.
By now you must be saying, aren’t there some drawbacks to this? Well, it does mean a little administrative overhead to manage the DNS records. It also means you have to actually think in order to choose good aliases. (Choosing bad ones may come back to haunt you.) Particularly if you have a robust development/QA lifecycle, there may be more administrative work, since you have many more systems to work with. Yes, there is some overhead with this strategy, but I think in most situations it will more than pay for itself over time.
Remember: choose an alias based on the function the system is intended to perform. It is perfectly fine to have many aliases pointing to the same system. Going back to the database scenario, if we have 15 applications that all use the same database server, yes, that means we would have 15 DNS aliases. It also means we can move any of those 15 databases and the only hard work is dealing with the individual database in question. Change is inevitable, but it doesn’t always have to be painful. Changing CNAME records is pretty easy compared to most alternatives. It’s not a panacea, but it solves a lot of problems before they become problems.
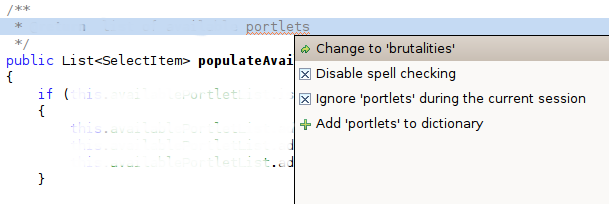
Brutalities
22 January 2009
An apt summary of my view, provided by Eclipse spell-check.
Maven, JAXB, and Workarounds
10 November 2008
We’re using Maven 2 at work to build our projects now. One of the projects uses JAXB to manage some XML documents. Well, the JAXB standard doesn’t say anything about how namespaces are handled when marshalling to XML, which means I can’t write XSLT against our output (FAIL). Sun’s JAXB implementation has a way to control namespace output, but it’s non-standard. Even worse, it changed between Java 5.0 and 6.0 (package rename), so code written against 5.0 will fail when running in a newer JVM.
I’m <a target=“_blank” href=“http://pragmaticintegration.blogspot.com/2007/11/moving-jaxb-20-applications-built-by.html”
not the only one who has had this problem, but I think my solution is different than any I’ve seen. It took me a long time to get Maven to cooperate, but I finally got it working. I believe I found a bug in Maven, but I haven’t looked at the source yet to verify it. Maven documentation is extremely lacking when it comes to explaining what’s really going on. Sadly, it’s the best thing out there; the only good thing I can say is Maven 2 is better than the original.
Here is the Java code and Maven POM excerpts necessary to explain my solution:
import com.sun.xml.bind.marshaller.NamespacePrefixMapper;
class PrefixMapper_JDK5 extends NamespacePrefixMapper {
@Override
public String getPreferredPrefix(String namespaceUri, String suggestion,
boolean requirePrefix) {
return suggestion;
}
}
//JDK 6 added "internal" to the package naming
import com.sun.xml.internal.bind.marshaller.NamespacePrefixMapper;
class PrefixMapper_JDK6 extends NamespacePrefixMapper {
@Override
public String getPreferredPrefix(String namespaceUri, String suggestion,
boolean requirePrefix) {
return suggestion;
}
}
public Object getNamespacePrefixMapper() {
Object r = null;
//the mapper classes should be compiled separately before this method
//is compiled so they match the proper JDK (-source and -target flags)
Class[] mapperList = {
//first one in list gets priority...
PrefixMapper_JDK6.class, PrefixMapper_JDK5.class
};
try { //there is a better way to implement this... you can figure it out
r = mapperList[0].getClass().newInstance();
} catch (Exception e) {
try {
r = mapperList[1].getClass().newInstance();
} catch (Exception ex) {}
}
return r; //null if neither class could be loaded
}
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
<excludes>
<!-- Maven is buggy here and will not remove the first
exclude line given, so the first one needs to be
bogus. -->
<exclude>==MavenBugWorkaround==</exclude>
<exclude>**/PrefixMapper_JDK5.java</exclude>
</excludes>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
<phase>compile</phase>
<configuration>
<source>1.5</source>
<target>1.5</target>
<!-- clears inherited exclude list
(except for 1st element) -->
<excludes/>
<!-- only uncompiled files will be looked at -->
<includes>
<include>**/*.java</include>
</includes>
</configuration>
</execution>
</executions>
</plugin>
XML
23 October 2008
I vote for making XML abuse a crime. People treat it like it’s AI or something – use it and your program magically “understands” things.
The application I’m calling has an XML format; our company has an XML format – I get to convert back and forth between the two. Our format is infinitely recursive… The business rules engine is XML-based. There are XML config files, schemas, wsdl files, build scripts, repository meta-data, entity mapping specifications, XSLT…
Someone please bring an end to all this misery. Stop using a document format for everything that’s not a document!
Older posts are available in the archive.